正则表达式是一串字符串,它描述了一个文本模式,利用它可以方便的处理文本,包括文本的查找、替换、验证、切分等。
语法
单个字符
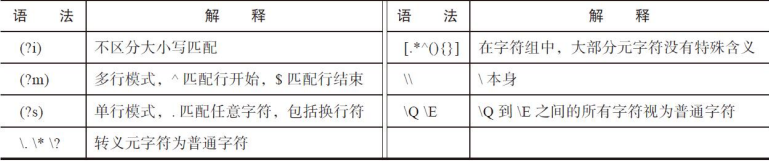
大部门的单个字符就是用字符的本身进行表示,但是有些字符使用多个字符表示,这些字符都以
\开头:
- 特殊字符:例如
\t- 八进制表示的字符:以
\0开头- 十六进制表示的字符:以
\x开头- Unicode编号表示的字符:以
\u开头- 斜杠本身:
- 元字符本身:如、,*
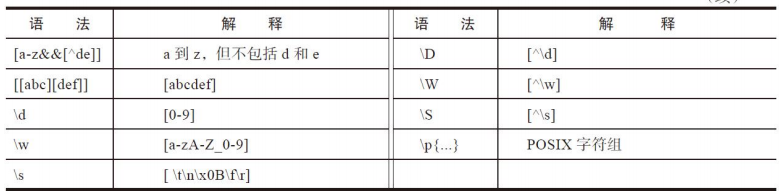
字符组
字符组有多种,包括任意字符,多个指定字符之一、字符区间、排除型字符组、预定义的字符组等。
.一般表示匹配除了换行之外的所有字符。例(a.f).以(?s)开头表示匹配任意字符,如(?S)a.f- 匹配组中的任意一个字符用
[]表示,如[a,b,c] - 匹配任意一个数字字符用连字符
-表示,如[0-9],[0-9a_zA_Z-],在字符组中如果想要匹配连字符本身需要转义或者放到字符组的最前面,如:[-a_z],[^a-z}表示匹配一个非小写字母的字符,如果写在字符组的中间则表示匹配自身。 - 预定义字符组:
.\d表示匹配一个数字字符,等同于[0-9].\w表示匹配一个单词字符,等同于[a-zA-Z_0-9].\s表示匹配一个空白字符,等同于[\t\n\f\r].\D表示匹配一个非数字字符,等同于[^\d].\W表示匹配一个非单词字符,等同于[^\w].\S表示匹配一个非空白字符,等同于[^\s] - 量词:指的的制定出现次数的元字符,如果要匹配这些字符需要转义。
+:表示前面字符一次或多次出现。(如ab+c能匹配abc,abbc,abbbc)*:表示前面的字符零次或者多次出现(如ab*c能匹配ac,abbc)?:表示前面的字符可能出现也可能不出现(如ab?c可以匹配ac,abc但是不能匹配abbc)量词的匹配默认是贪婪的,即尽量会匹配到最后一个,如果只想匹配到第一个则在后面加
?
更为通用的表示出现次数的语法是{m,n},出现次数从m到n,包括m和n,如果n没有限制不写,m和n一样写{m}
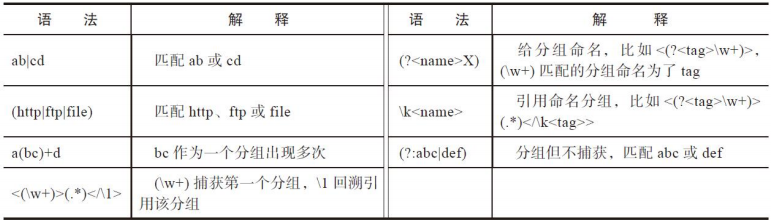
- 表达式用
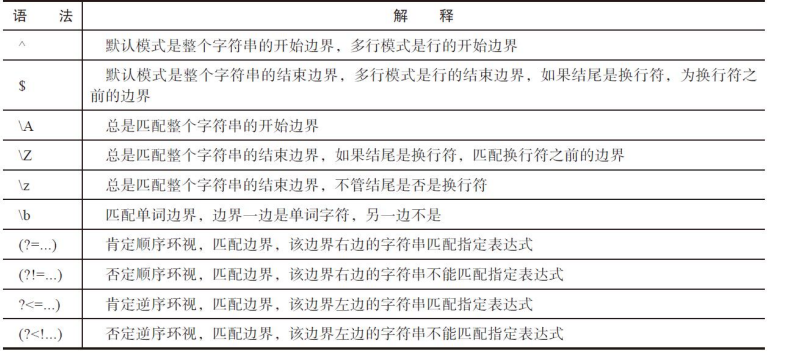
()括起来,表示一个分组。 - 特殊边界匹配:
常用的表示特殊边界的元字符有:^(字符组外匹配字符串的开始,多行匹配模式中匹配行的开始)$(匹配字符串的结束,多行匹配模式中匹配行的结束)\A (匹配字符串的开始边界)\Z(匹配字符串的结束边界)\z(匹配字符串的结束边界)\b(匹配单词的边界)
语法总结
- 单个字符语法
![]()
- 字符组语法
![]()
![]()
- 量词语法
![]()
- 分组语法
![]()
- 边界和环视语法
![]()
- 匹配模式和转义语法
![]()